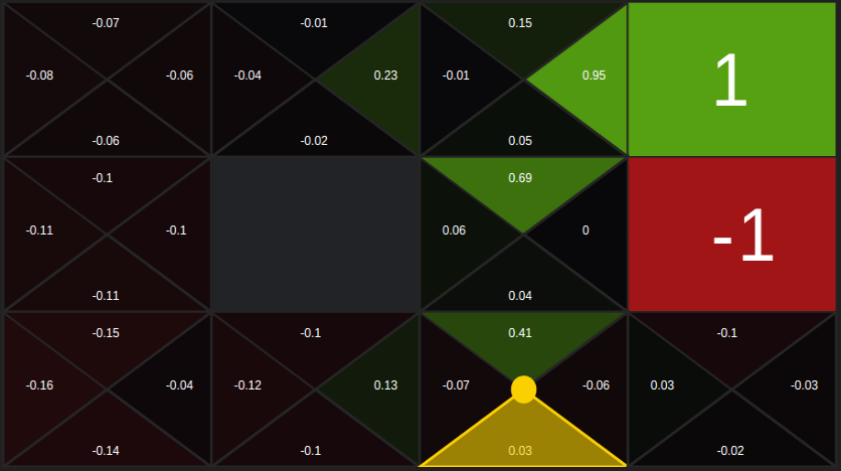
Q-learning Simulator
In this simple 4x3 grid-world, Q-learning agent learns by trial and error from interactions with the environment. Agent starts the episode in the bottom left corner of the maze. The goal of the agent is to maximize its total (future) reward. It does this by learning which action is optimal for each state. The action that is optimal for each state is the action that has the highest long-term reward. Episode terminates when the agent reaches +1 or -1 state, in all other states agent, will receive an immediate reward -0.1. If the agent enters the wall it bounces back. At the beginning of each game, all Q values are set to zero.